Improve Warehouse Productivity using Spatial Clustering with Python
Improve Warehouse Picking Productivity by Grouping Orders in Batches using Picking Location Spatial Clusters
Improve Warehouse Picking Productivity by Grouping Orders in Batches using Picking Location Spatial Clusters
Two levers of Optimization
In the first article, we built the basis to estimate the total picking route walking distance for a set of orders using:
- Warehouse Mapping: link each order line with the associated picking location coordinate (x, y) in your warehouse
- Distance Calculating: function calculating the walking distance from two picking location
We also decided to take a simple approach for
- Picking Route Design: given a choice of several picking locations, the warehouse picker will always choose to go to the closest (Next Closest Location Strategy)
- Order Waving: orders are ordered and grouped in waves by receiving time from OMS (TimeStamp)

Before looking at complex algorithms, we can find insights on optimising our algorithm with simple solutions.
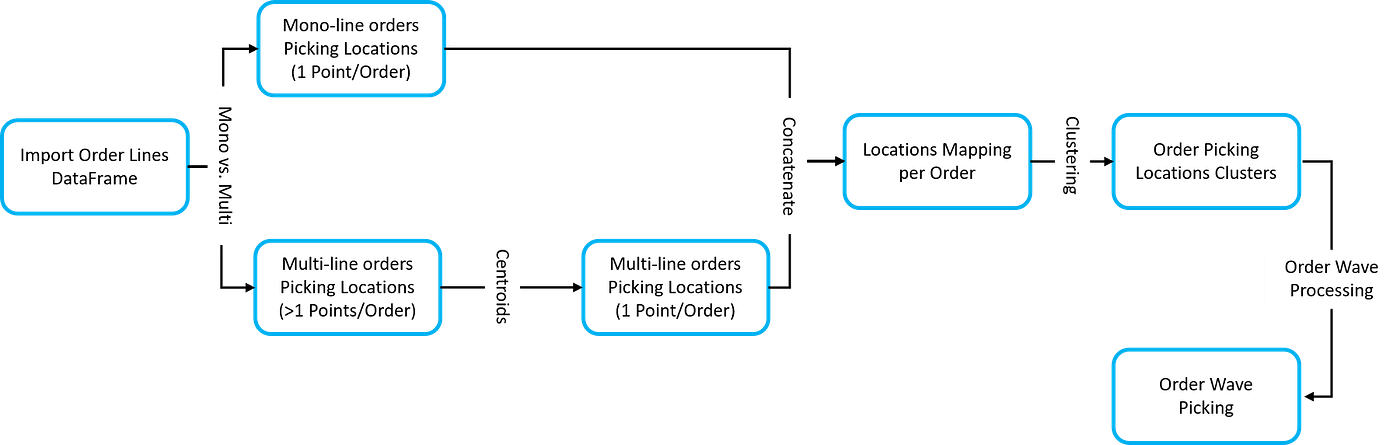
Order Wave using Picking Locations Clustering
Single-line orders have the advantage of being located in a single storage location; grouping several single-line orders by cluster can ensure that our picker will stay in a delimited zone.
Where single-line orders are located?

Function: Calculating the number of single-line orders per storage Location (%)
Code
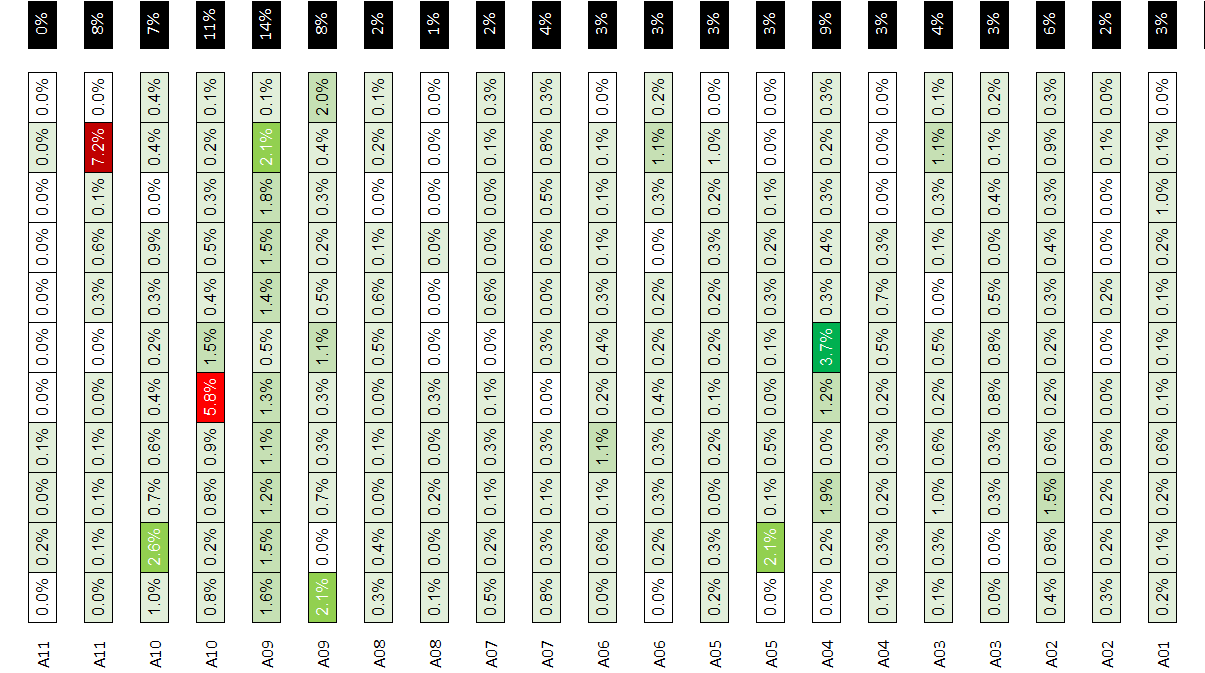
Insights: let us take the example of the distribution above
- Scope: 5,000 order lines for 23 aisles
- Single line orders: 49% of orders located in alleys A11, A10, and A09
1. Picking locations clustering using Scipy
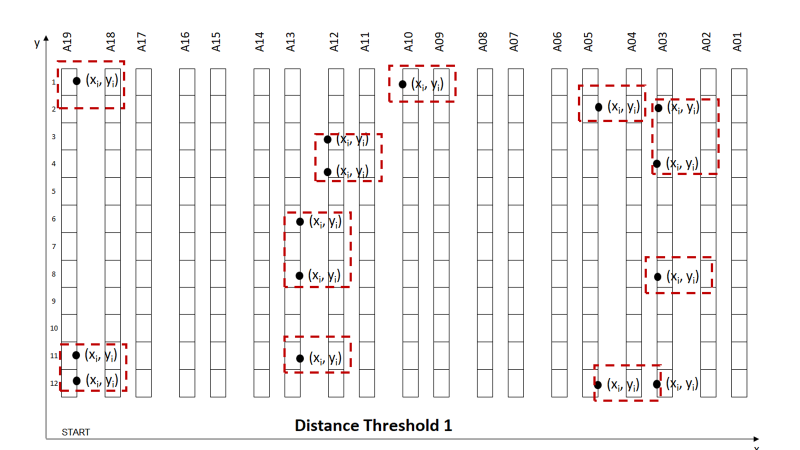
Idea: Picking Locations Clusters
Group picking locations by clusters to reduce the walking distance for each picking route. (Example: the maximum walking distance between two locations is <15 m)
Spatial clustering is the task of grouping together a set of points in a way that objects in the same cluster are more similar to each other than to objects in other clusters.
Here, the similarity metric will be walking distance from one location to another.
For instance, I would like to group locations to ensure the maximum walking distance between two locations is 10 m.
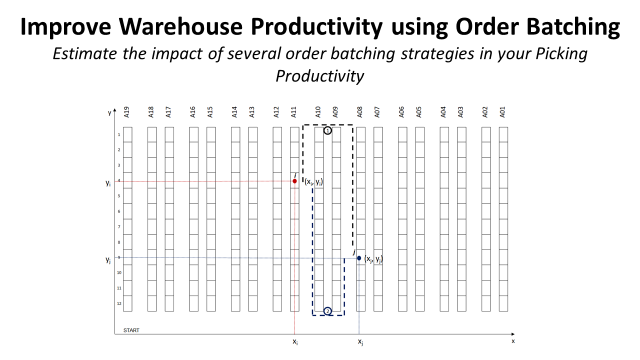
Challenge 1: Euclidean Distance vs. Walking Distance
For our specific model, we cannot use conventional clustering methods using Euclidean Distance.
Indeed, walking distance (using the distance_picking function) is different from Euclidean Distance.
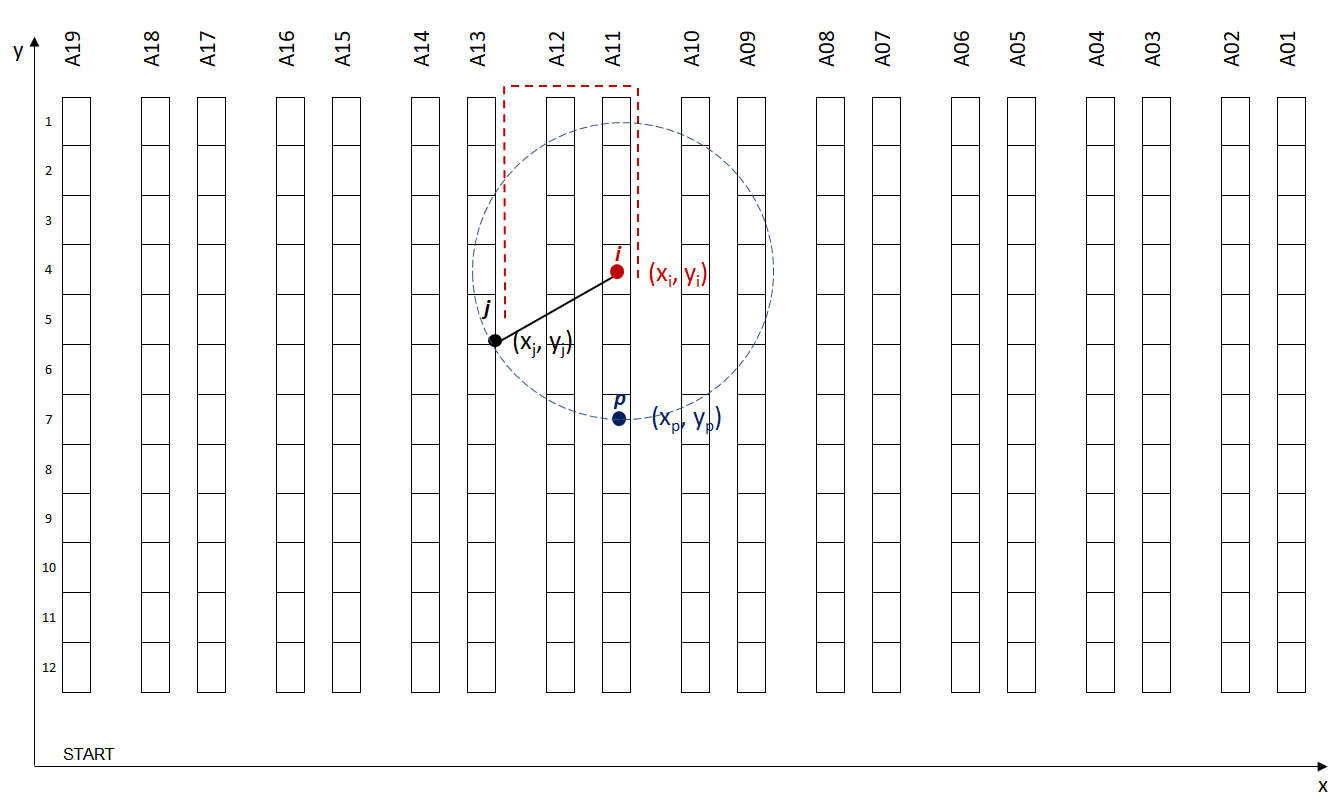
For this specific example, Euclidean distances between i (xi, Yi) and the two points p (x_p, y_p) and j (x_j, y_j) are equal.
But if we compare picker Walking Distance, p(x_p, y_p) is closer.
For this model, Picker's Walking Distance is the specific metric that we want to reduce.
Therefore, the clustering algorithm should use our custom-made distance_walking function for better performance.
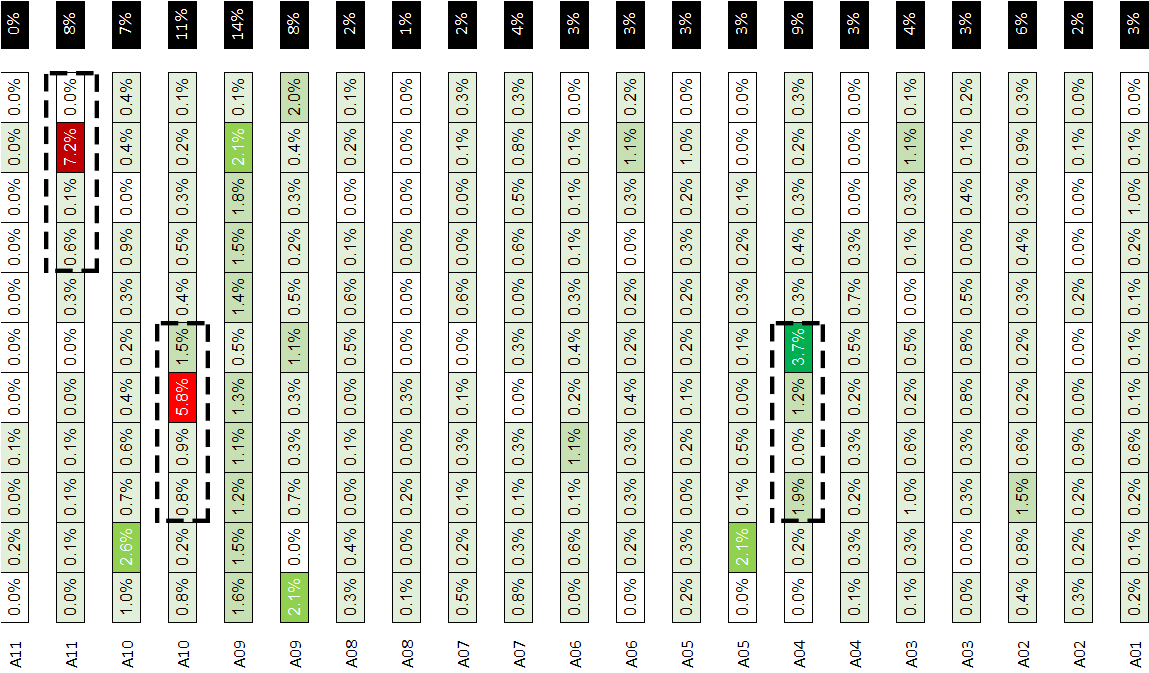
Example: Locations Clustering within 25 m distance (5,000 order lines)
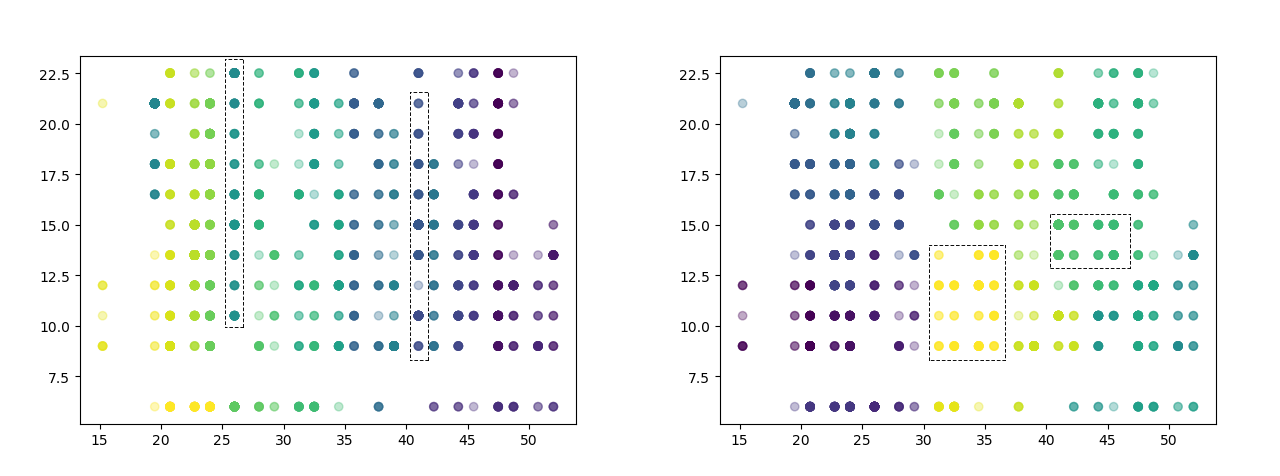
The left example using Walking Distance is grouping locations within the same aisle, reducing picking route distance; while the right example can group locations covering several aisles.
Function: Clusters for Single Line Orders using Walking Distance
For a set of orders, lines extract single lines (df_orderlines) orders and create clusters of storage locations within a distance (dist_method) using the custom distance function (dist_method).
Python code below uses Scipy’s ward and fcluster functions to create clusters of Picking locations using the distance_func metric (walking distance).
Code
Function: Single Line Orders Mapping with ClusterID
For a set of orders, lines extract single lines (df) orders, clusters id and orders number this function you map your Dataframe with cluster ID for wave creation.
Code
Picking locations clustering for Multi-line Orders
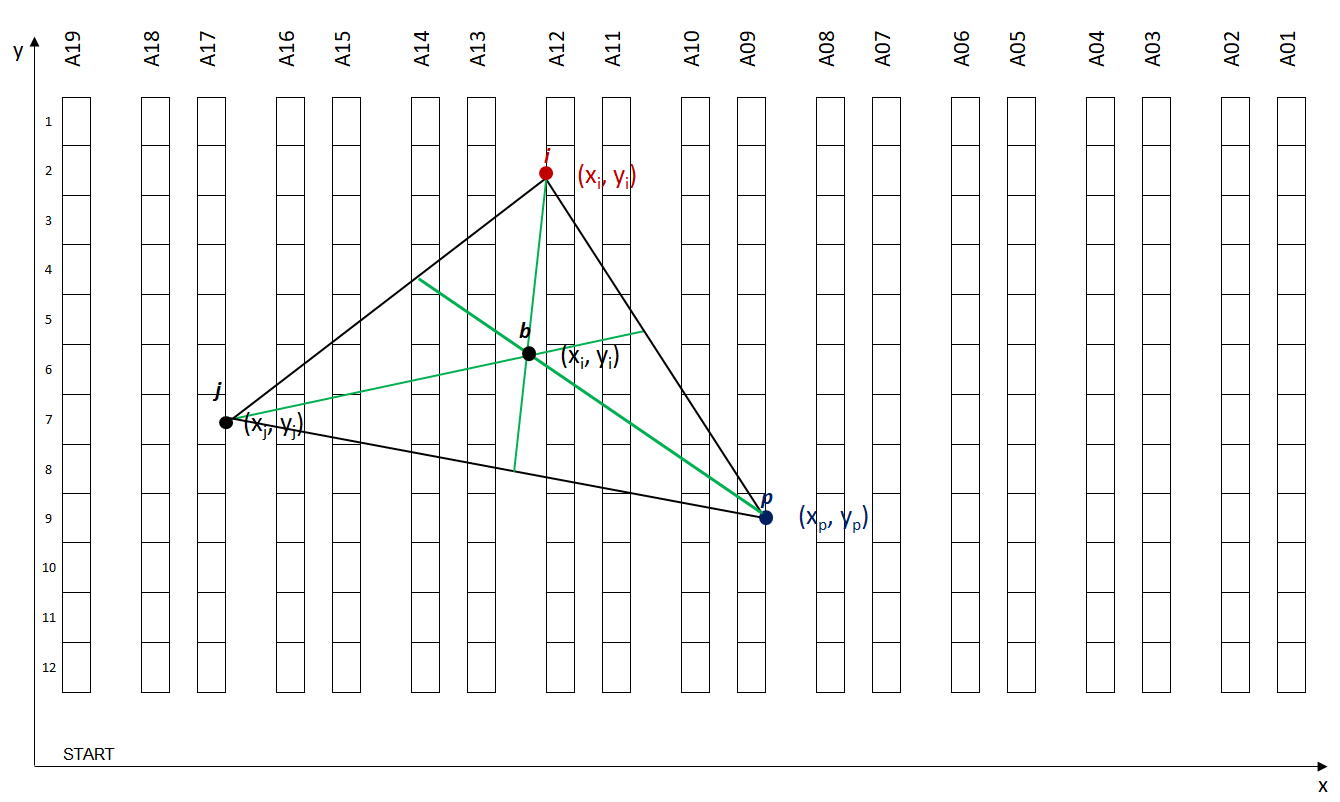
Function: Centroid for every multi-line order
Unlike single-line orders, multi-line orders can cover several picking locations. However, we can apply the same methodology applied to the centroids of storage locations.
Example: Order with 3 lines covering 3 different picking locations
Code
After using this function, we return to the mono-line orders situation with a single point (x, y) per order.
We can then apply clustering to these points by trying to group orders per geographical zone with maximum distance conditions.
Model Simulation
We have several steps before picking routes to create using wave processing.
At each step, we have a collection of parameters that can be tuned to improve performance:
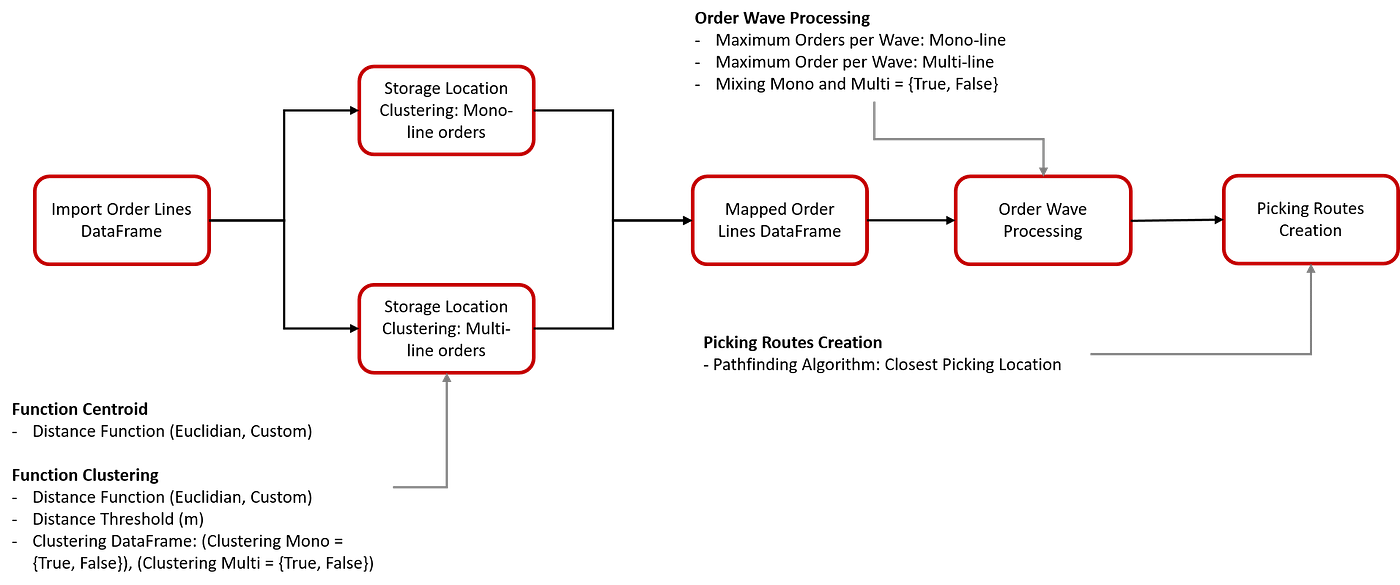
Comparing three methods of Wave Processing
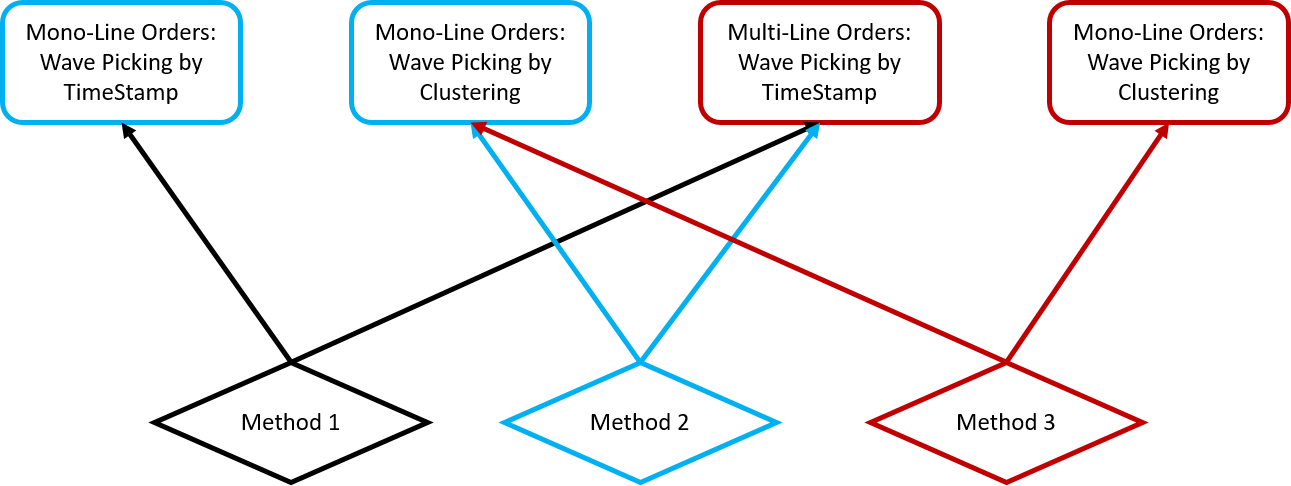
We’ll first assess the impact of Order Wave processing by clusters of picking locations on total walking distance.
We’ll be testing three different methods.
- Method 1: We do not apply clustering (i.e Initial Scenario)
- Method 2: We apply clustering on single-line orders only
- Method 3: We apply clustering to single-line orders and centroids of multiline orders.
Scenario for Simulation
- Order lines: 20,000 Lines
- Distance Threshold: Maximum distance between two picking locations (distance_threshold = 35 m)
- Orders per Wave: orders_number in [1, 9]
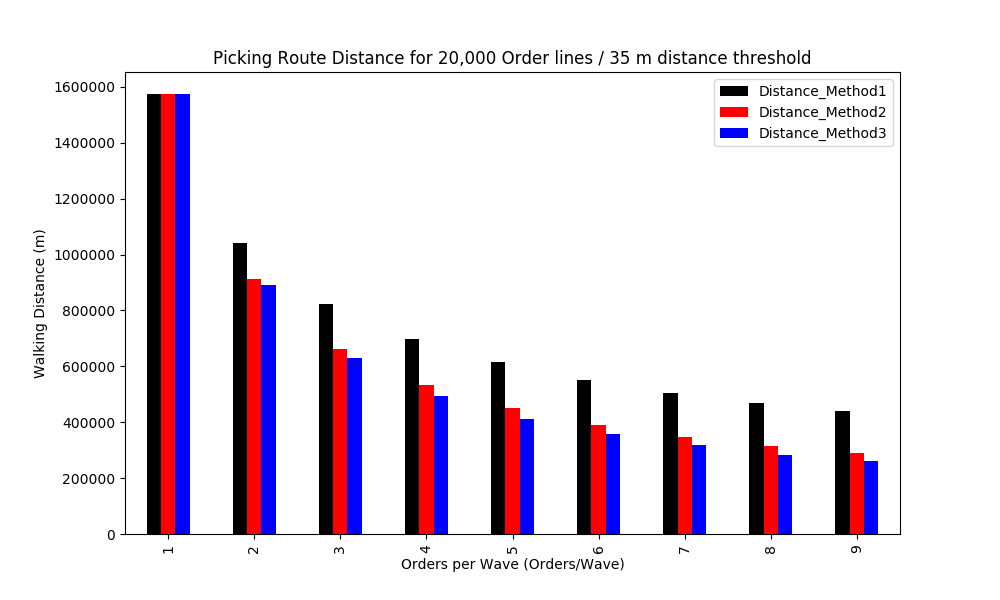
Results
- Best Performance: Method 3 for nine orders/Wave with 83% reduction of walking distance
- Method 2 vs. Method 1: Clustering for mono-line orders reduces the walking distance by 34%
- Method 3 vs. Method 2: Clustering for mono-line orders reduces the walking distance by 10%
Tuning Distance Threshold for Clustering
Now that we validated our first assumption that Method3 is the best for our particular scenario (20,000 order lines, 35 m Distance Threshold).
Let us look at the Distance Threshold impact on total walking distance.
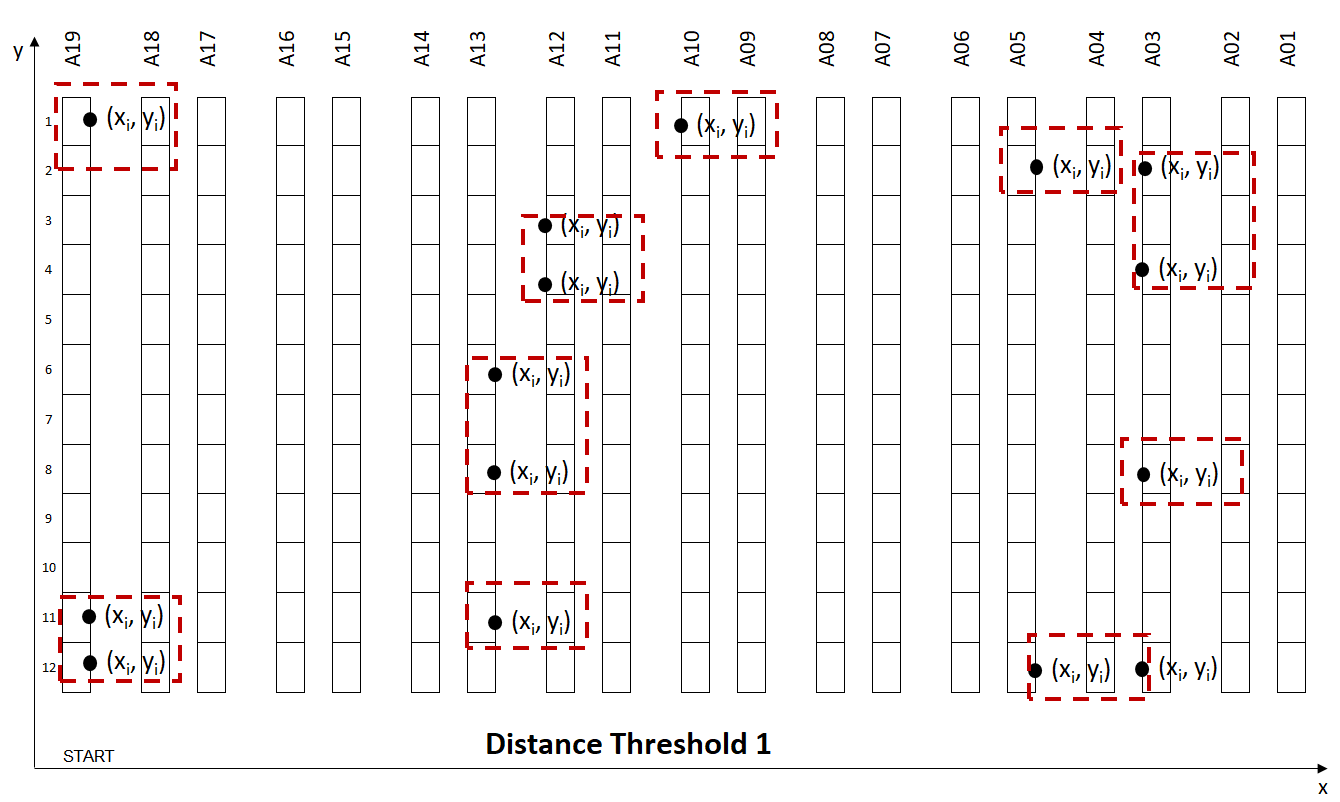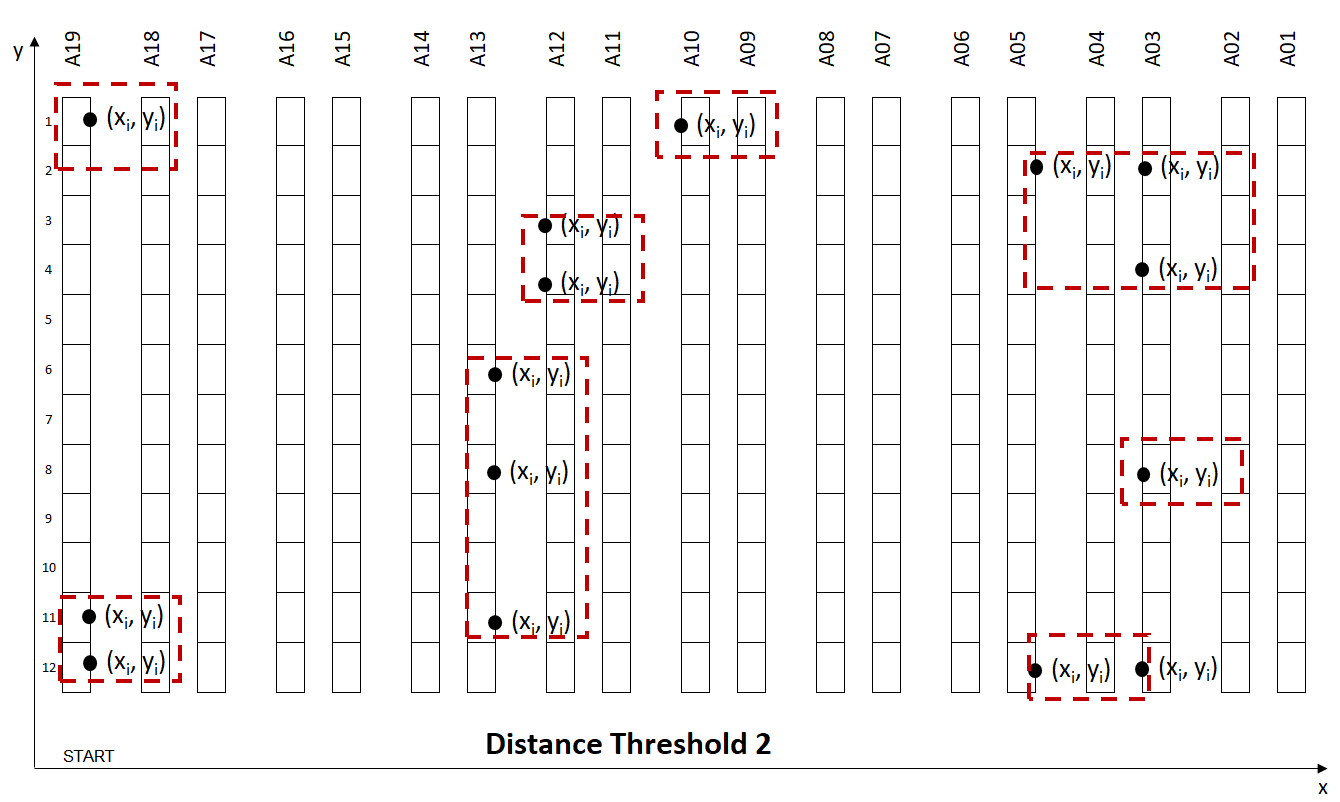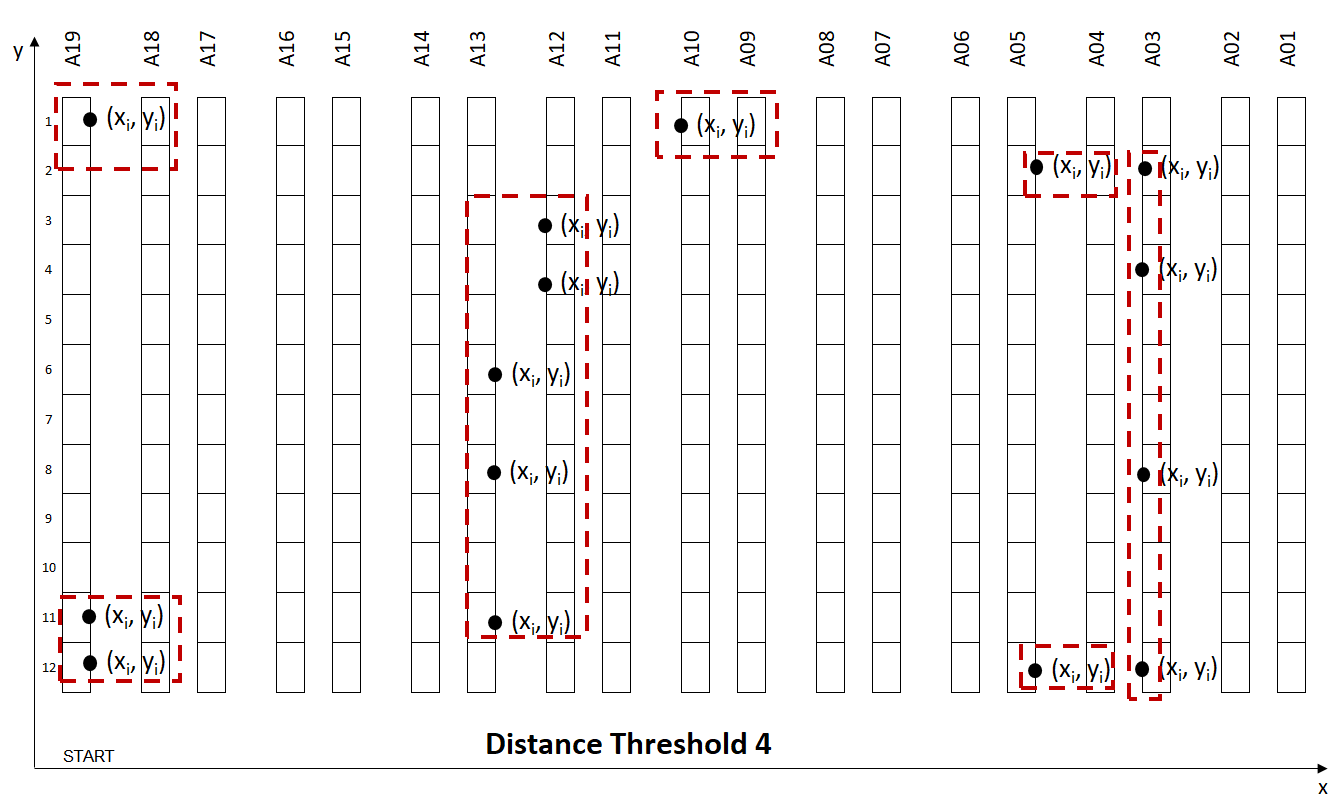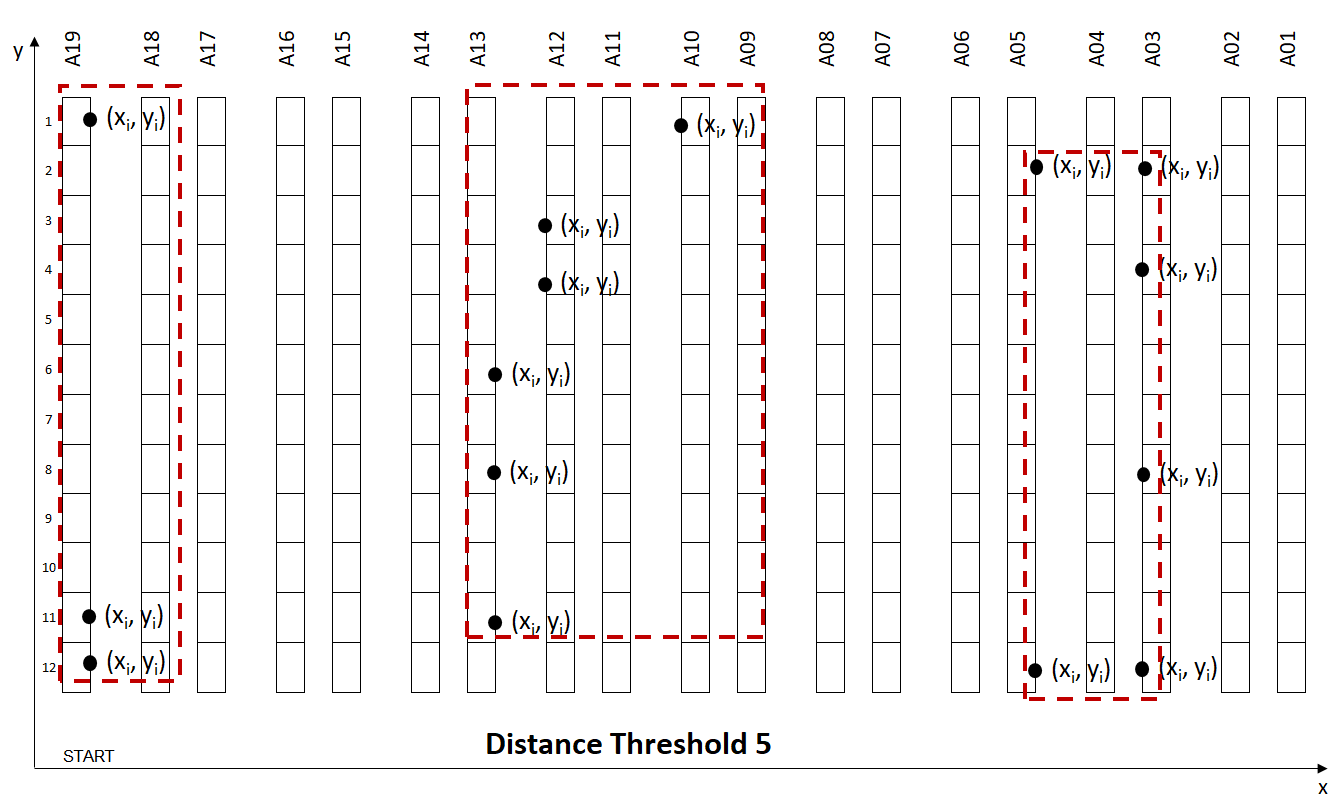
The trade-off between Walking Distance between two locations and Wave Size:
- Low Distance: The walking distance between two locations is low, but you have fewer orders per wave (more waves)
- High Distance: The walking distance between two locations is higher but you have more orders per wave (fewer waves)
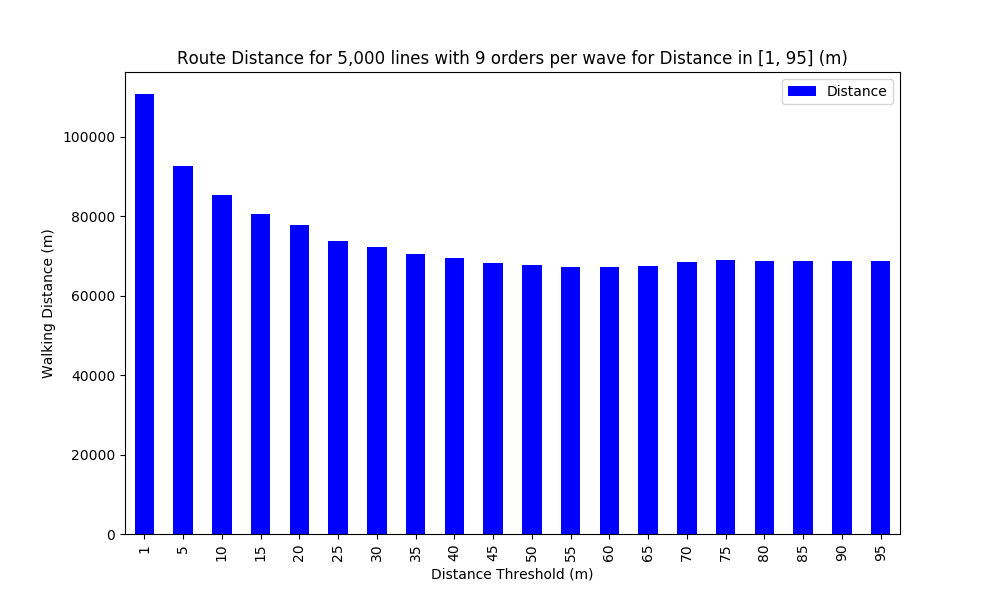
We can find a local minimum, for Distance_Threshold = 60 m, where the distance is reduced by 39% vs. Distance_Threshold = 1 m.
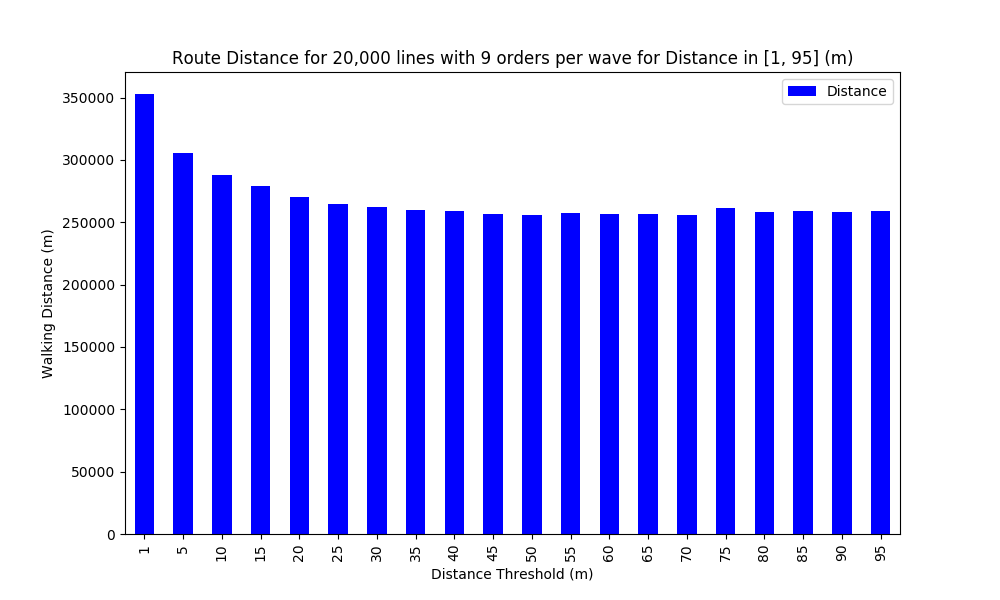
We can find a local minimum for Distance_Threshold = 50 m, where the distance is reduced by 27% vs. Distance_Threshold = 1 m.
Next Step
Based on this feedback, the next steps will be:
- Picking Route Creation: For a list of Picking Locations, how can we find the best route minimising walking distance?
 Samir Saci
Samir Saci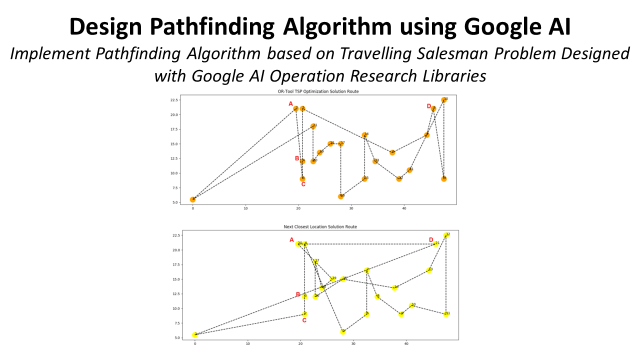
About Me
Let’s connect on LinkedIn and Twitter, I am a Supply Chain Engineer that is using data analytics to improve logistics operations and reduce costs.
If you’re looking for tailored consulting solutions to optimize your supply chain and meet sustainability goals, please contact me.
References
[1] Samir Saci, Improve Warehouse Productivity using Order Batching with Python
Samir Saci