Deep Reinforcement Learning for AGV Routing
Increase Warehouse Productivity by using Reinforcement Learning for Automated Guided Vehicles Routing
In a Distribution Center (DC), walking from one location to another during the picking route can account for 60% to 70% of the operator’s working time.
Reducing this walking time is the most effective way to increase overall productivity.
In a previous series of articles, I have shared several methods using optimization strategies to reduce the walking distance of operators in your warehouse.
These methods have limits when you have a large picking area.
Therefore, automated solutions, using Automated Guided Vehicles (AGV) that bring the shelves directly to the operators, are now very popular.
This article will explain how Reinforcement Learning can be used to organize the routing of these robots to ensure optimal productivity.
💌 New articles straight in your inbox for free: Newsletter
From Man-to-Goods to Goods-to-Man
Early adopters of this shift from a manual operation — man-to-goods — to goods-to-man are E-Commerce companies.
Their priority is to deliver on time with the highest productivity possible like explained in the video below.
Because of significant fluctuations in their volumes (Promotions, Festivals), a broad range of references, and a shortage of labour resources, automation is a must for them.
Goods-to-person picking using Automated Guided Vehicles
Goods-to-Person Picking solutions deliver items directly to your operator in their pick stations. You eliminate all non-value-added time needed for operators to search for items.

The goods are stored on shelves that can be moved by these vehicles directly to picking stations where the operators will take the needed quantity to prepare their orders.

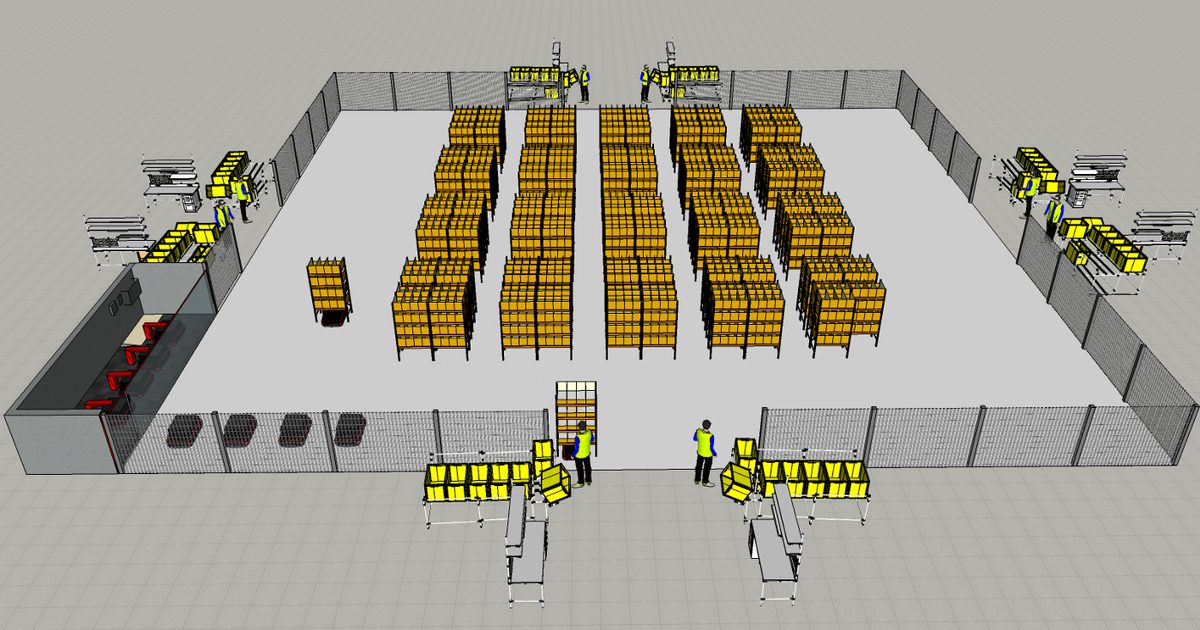
AGV Installation Layout
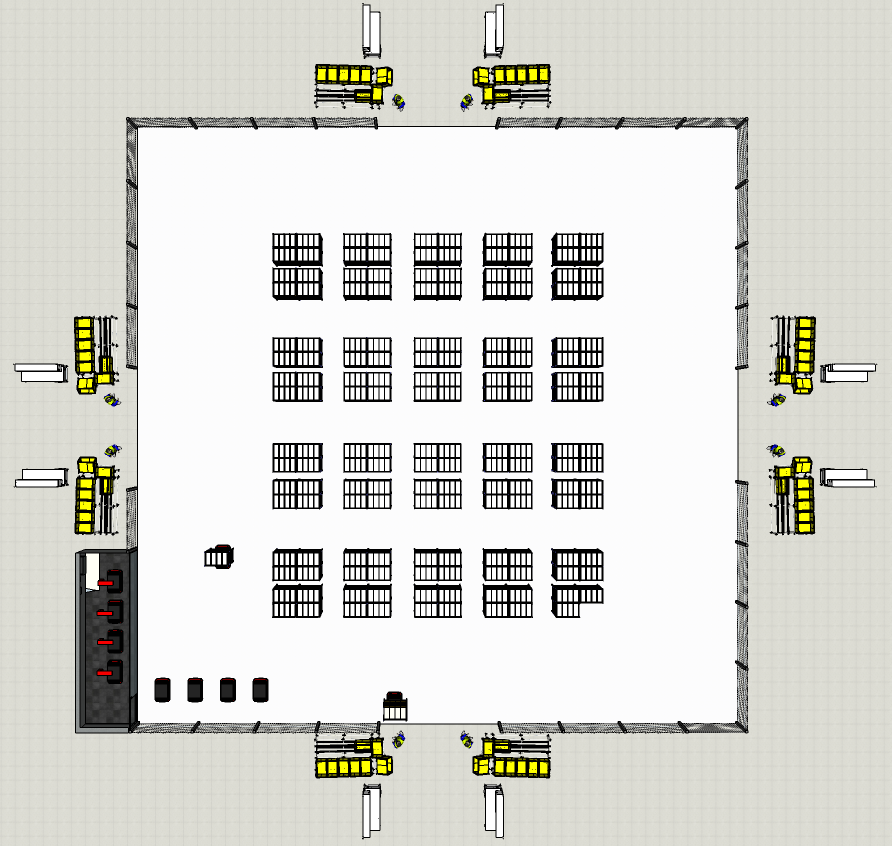
In this layout, you have
- 8 Picking Stations grouped by two with 1 Operator per Station
- 16 (8 x 2) alleys of shelves
- 1 charging station for the vehicles
Build your Optimisation Model
Create a Topological Map of your AGV Layout
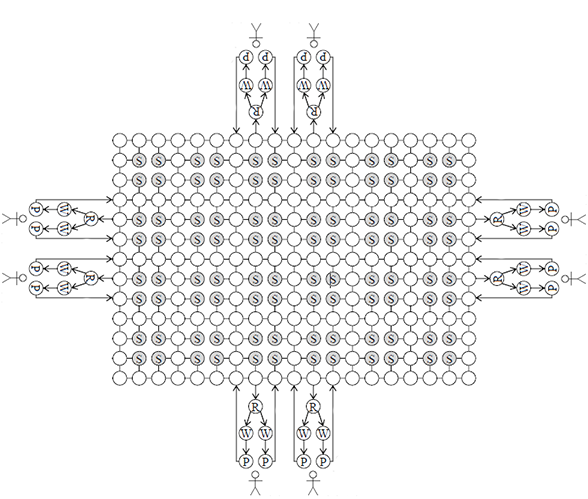
Our layout is modelled by a graph G(N; E)
- N is the set of nodes (circles above)
- E is the set of edges (solid lines and arrows)
- S represent the shelves (filled grey nodes indicate the places to store shelves)
- R represents the points where AGVs rotate shelves.
- W represent the waiting points where your AGV with a shelf waits for the completion of the picking activity of the AGV that arrived at the picking station before
- P represents picking points at where the picker will take the products
This mapping will be included in an AGV Picking Simulation Model that will be used to test our routing strategies.
Pathfinding using Dijkstra's Algorithm
Dijkstra’s algorithm is an optimisation algorithm that solves the single-source shortest path problem for a directed graph with weighted edges (non-negative weights).
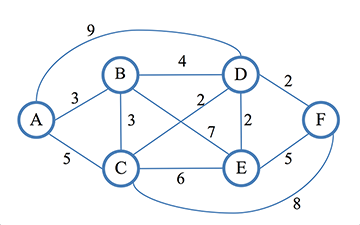
This length can be the absolute length of the path, it can also be computed considering other constraints situated on the edges or the nodes.
We can use three types of weight from the node u to the node v noted w(u, v)
- Shortest Distance Route Weight: w(u, v) = d(u, v) (1)
with d(u, v) the distance between u and v
- Objective: take the route with the shortest distance - Shortest Travel Time: w(u, v) = d(u, v)/s(u, v) + r(u, v) (2)
with s(u, v) the AGV translational speed and r(u, v) the time need for all rotations
- Objective: take the route with the shortest travel time - Congestion Avoidance: w(u, v) = d(u, v)/s(u, v) + r(u, v) + Co(u, v) (3)
with o(u, v) the number of AGVs planned to pass through the edge and C is the constant value for adjusting the weight
- Objective: take the route that avoids congestion with other AGVs
Reinforcement learning approach
At time t, we define the state of the warehouse by:
- Spatial locations of all the active vehicles (AGV that have routes assigned)
- Spatial locations of all the active shelves (shelves that have items to be picked)
- Workstations Order Lines Allocations (stations where items need to be transferred)
These parameters will vary in time, therefore let’s use a reinforcement learning approach to select the optimal route from these candidates in accordance with this state.
Agent Rewarding Strategies
Your learning agent is rewarded for arriving at a destination node using three different reward value approaches.
- Productivity: the number of items picked per labour-hour during the period from the AGV starting at an origin point to it arriving at a destination.
- Idle time: time that a picker waits for the next AGV after picking items from a shelf with an AGV.
- Speed: average speed of an AGV from an origin point to a destination
Simulation
Scenario
This first simulation is based on three days of picking: day 1 for training, days 2 and 3 for testing.
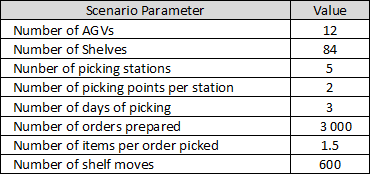
The results of the RL model will be compared with two simple route planning
strategies.
- Random: select a route among the shortest distance route, the shortest travel time route and the congestion avoidance route
- Congestion: choose the congestion avoidance route at all times
Results
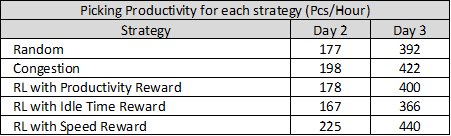
It is surprising to see that the productivity reward performs less than the speed reward approach.
Maximising each AGV's productivity may not be the best approach for collaborative work between vehicles to ensure high global productivity.
The congestion strategy is performing well while requiring less computing resources vs. the RL approach when congestion is the main bottleneck (i.e. when you have a high density of vehicles running simultaneously).
Next Steps
These results are based on a specific layout with only two days of picking activity.
To better understand this approach, I will explain how to build an AGV picking simulator and implement routing strategies in the next article.
This model should be tested on a variety of order profiles to test the impact on productivity by tuning:
- Number of lines per order (moves per order)
- Quantity of units picked per line
- Range of active SKUs
The choice of the strategy may vary if you have a promotion event on a particular group of SKUs, a shopping festival (Black Friday, 11.11) or during the low season.
About Me
Let’s connect on LinkedIn and Twitter, I am a Supply Chain Engineer that is using data analytics to improve logistics operations and reduce costs.
If you’re looking for tailored consulting solutions to optimize your supply chain and meet sustainability goals, feel free to contact me.